Small Language Models vs Large Language Models: The 2025 Enterprise Playbook for Cost, Privacy and Accuracy
Generative AI in 2025 is not “always use the biggest model.” This practical guide explains Small Language Models vs Large Language Models for real enterprise projects cost, privacy, latency, and accuracy. Learn when to choose SLM, LLM, or a hybrid setup so your AI stack is fast, affordable, and production-ready...

Over the last year, I have spoken with CTOs, developers, researchers, and even non-technical business leaders who all asked the same question:
“Should we use a SLMs vs LLMs, Small Language Model or a Large Language Model for our AI roadmap?”
This blog is for you if you are:
- A CTO/CIO/CDO planning your 2025 GenAI architecture
- An AI engineer or developer selecting the right model for production
- A researcher studying model-size trade-offs
- A business leader who wants clear, no-nonsense guidance
- A student or enthusiast exploring modern AI systems
My goal is to give you a human, practical, real-world explanation that cuts through noise and helps you make the right decision, powered by what I’ve seen in actual enterprise deployments.
By the end, you will know when to use an SLM, when to use an LLM, and when to combine both in a hybrid architecture for maximum value in 2025.
SLMs vs LLMs — simple explanation with real-world lens
When people hear “Large Language Model,” they often assume “bigger is automatically better.” In implementation, that is not always true.
- Large Language Models (LLMs) are massive models like GPT‑4‑class, Claude Opus, or Gemini Ultra. They are excellent generalists: strong at reasoning, creativity, and open‑ended problem solving. But they often come with higher cost, more latency, and tougher conversations around data privacy and governance.
- Small Language Models (SLMs) are compact models such as Llama‑3 8B, Mistral 7B, Phi‑3 Mini, and newer enterprise SLMs. They are cheaper, faster, and easier to fine‑tune or run on‑prem. When you specialise them on a specific domain using your own data, they can match or even beat LLMs on many enterprise tasks.
Think of it this way:
- LLMs are generalists – like a top consultant who can reason about anything.
- SLMs are specialists – like an in‑house expert who knows your company’s documents deeply.
A real story: when an SLM beat an LLM
Imagine an internal knowledge assistant for a financial company.
The initial expectation from leadership is familiar:
“Use the best model. Use GPT‑4‑level capability.”
The team starts with an LLM and gets good answers, but three big problems appear quickly:
- Latency – responses feel slow at scale, especially during peak hours.
- Cost – with 10 lakh+ queries per month, the monthly bill becomes a serious concern.
- Privacy & compliance – strict financial regulations make sending detailed internal data to external endpoints uncomfortable.
The team then tries a Small Language Model (e.g., a 7–8B parameter model) deployed on their own infrastructure, combined with:
- RAG (Retrieval‑Augmented Generation) – the model looks up the company’s internal documents before answering.
- LoRA/QLoRA-based fine‑tuning – light‑weight adaptation using the company’s ticket history and policy documents.
What changes:
- Accuracy on a curated test set of real questions jumps from “okay” to “reliably production‑ready.”
- Latency drops to sub‑second answers for most queries.
- Cost becomes mostly fixed infra + electricity, instead of unpredictable API bills.
The leadership’s reaction is simple:
“So for this use case, we don’t actually need the biggest LLM?”
Exactly. For narrow, policy‑driven internal Q&A, a tuned SLM is often the right tool.
Where an LLM is still absolutely necessary
Now consider a different project: generating long, complex compliance reports or drafting multi‑page legal documents that involve 50–70 steps of reasoning and cross‑references.

Even after fine‑tuning, SLMs typically struggle with:
- Very long chains of thought with many dependencies.
- Multi‑page document generation that must maintain structure, tone, and accuracy.
- Highly open‑ended analytical tasks with many variables and constraints.
Here, a Large Language Model still has a clear edge. For tasks like:
- Drafting complex contracts or legal opinions.
- Creating detailed multi‑step analytical reports.
- Solving novel, ambiguous problems with many moving parts.
An LLM often becomes the safest and most efficient choice.
In many real systems, the best solution is hybrid:
- An SLM handles understanding the query, gathering relevant context, and answering simpler questions.
- An LLM is called only for the hardest part – generating the final long-form legal draft, compliance report, or deeply reasoned explanation.
Cost: how big is the difference in practice?
Enterprises usually feel the cost gap in high‑volume use cases like support bots, internal assistants, or ticket automation.
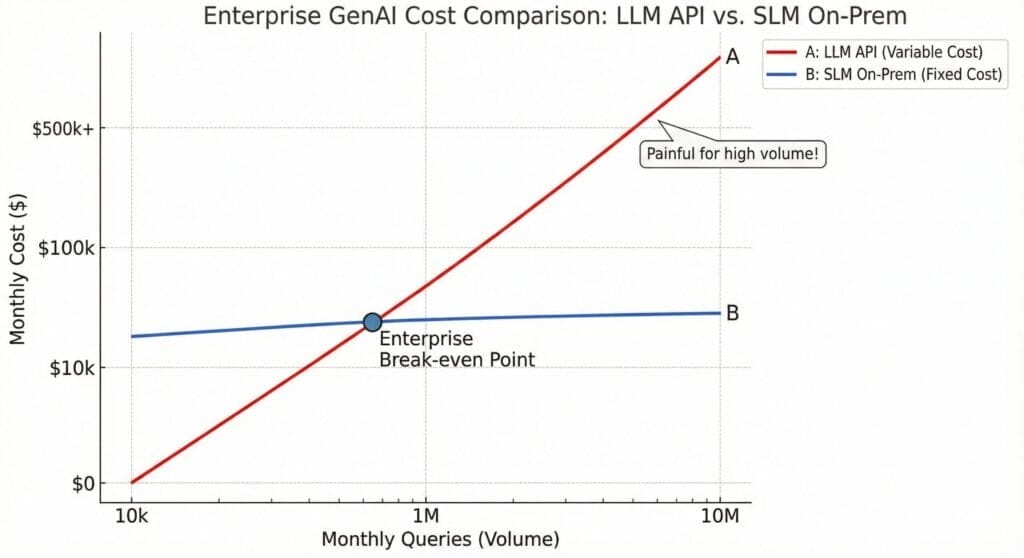
Typical pattern:
- LLM‑only architecture
- Per‑token pricing means cost scales directly with volume and prompt size.
- With lakhs of monthly queries, bills can easily reach the “multiple lakhs per month” range.
- This is fine for high‑value, low‑volume use cases, but painful for repetitive queries.
- SLM‑based architecture
- Models run on your own GPU servers or a small, dedicated cluster.
- You pay mainly for hardware, electricity, and maintenance.
- The effective per‑query cost is often 50–90% lower compared to premium LLM APIs, especially for short, repetitive queries.
For many CTOs, this transforms the conversation from “Can we afford this?” to “Why didn’t we move routine workloads to SLMs earlier?”
Where SLMs shine in real enterprise use cases
SLMs tend to shine when tasks are:
- Repetitive – same patterns again and again.
- Domain‑specific – grounded in your own policies, documents, and SOPs.
- Structured – clear inputs and expected types of outputs.
Examples where SLMs often work extremely well:
- Customer support FAQs and first‑line responses.
- Internal policy answering for HR, IT, procurement, finance.
- ITSM and HR ticket triage and simple resolution.
- Retail product search and catalog Q&A.
- Healthcare and insurance guideline lookup (under strict guardrails).
- Document classification and structured summarization.
If your knowledge lives in handbooks, SOPs, PDFs, and internal wikis, an SLM with RAG and light fine‑tuning can usually become a very strong domain expert.
For developers and AI engineers, SLM + RAG + LoRA is also easier to iterate: you can ship new versions weekly without depending on a foundation-model vendor.
Where LLMs still win — and how to use them strategically
Despite the rise of SLMs, there are clear use cases where LLMs remain the right choice in 2025:
- Deep, multi‑step reasoning with lots of uncertainty.
- Highly creative content: campaigns, narrative concepts, unique ideas.
- Long, complex document drafting (legal, compliance, strategy).
- Big, complex codebases and refactoring tasks.
For AI researchers, this matches what scaling laws suggest: larger models still tend to handle the most complex reasoning and generalisation tasks better.
The key is not to use an LLM for everything. Instead:
- Reserve LLMs for the hard 10–20% of interactions where their extra capability creates real business value.
- Let SLMs handle the bulk of simple or moderately complex traffic.
This is how you get enterprise‑grade cost efficiency without sacrificing quality on critical tasks.
Data privacy and compliance: why SLMs are often default in regulated industries

In banking, healthcare, insurance, public sector, and cybersecurity, you often hear a statement like:
“If the model is not running inside our network, we won’t use it.”
Reasons:
- Sensitive data (financial transactions, health records, PII, legal docs) cannot be freely sent to external APIs.
- Regulators and auditors expect strict control, logging, and explainability over what happens with data.
SLMs fit this world very well because:
- They can be run entirely on‑premises or inside a private cloud/VPC.
- No data has to leave your security perimeter.
- It becomes much easier to align with GDPR, HIPAA‑style rules, RBI‑like guidelines, ISO 27001, and internal InfoSec policies.
For many regulated organisations, the natural pattern is:
- SLM‑first for all workloads involving sensitive or regulated data.
- LLM selectively for non‑sensitive or anonymised use cases, or behind strong anonymisation and masking layers.
Deployment speed: SLMs as your “fast PoC engine”
One more hidden advantage of SLMs is time to first value.
Getting a big external LLM into a large enterprise usually involves:
- Vendor onboarding and commercial negotiation.
- Security, legal, data‑protection, and procurement reviews.
- Cloud and network configuration, observability, and rate‑limit discussions.
This can easily take weeks before a single real user sees value.
With SLMs, especially open or enterprise SLMs that can be deployed on existing infra:
- Your data never leaves the network, so governance is simpler.
- Internal teams can spin up PoCs on known hardware quickly.
- Techniques like LoRA, QLoRA, and PEFT make fine‑tuning light and fast.
This is why many GenAI teams now treat SLMs as their default PoC engine:
- Build a working internal prototype in a few days.
- Prove value with internal users.
- Then decide where, if anywhere, external LLMs are worth adding.
SLMs vs LLMs Hybrid – one-glance enterprise view
Enterprise view in 2025
| Dimension | SLM (Small Language Model) | LLM (Large Language Model) | Hybrid (SLM + LLM) |
| Best for | Repetitive, domain‑specific workflows | Complex, open‑ended tasks and deep reasoning | Organisations with a mix of simple and complex workloads |
| Cost | Low; runs on few GPUs/on‑prem; cheap per query | Higher; per‑token API or heavy infra | Optimised; SLM handles volume, LLM only for edge / high‑value cases |
| Data privacy | Strong; can stay fully on‑prem/VPC | Depends on vendor and setup; more scrutiny for external APIs | Sensitive data to SLM, generic tasks to LLM |
| Latency | Fast; often sub‑second | Slower for heavy prompts and long reasoning | Low‑latency traffic to SLM, complex tasks to LLM |
| Customisation | Easy, cheap fine‑tuning on your own data | Harder and more expensive to deeply adapt | SLM specialised, LLM used as general‑purpose reasoner |
| Ideal owner | Platform/ML teams, internal AI CoE | Central AI team with clear high‑value use cases | Enterprise architecture / platform teams orchestrating both |
This table is what many CTOs and non‑tech leaders will screenshot and share.
A simple decision framework anyone can use
Here is a decision rule you can explain even to non‑technical stakeholders:

- Choose an SLM if:
- The task is predictable, repetitive, and domain‑specific (policies, FAQs, SOPs).
- You care a lot about cost, latency, and privacy.
- You are ready to fine‑tune on your own data and set up RAG.
- Choose an LLM if:
- The task needs deep reasoning, creativity, or long-form generation.
- You are dealing with complex, open‑ended problems or large documents.
- The business value per query justifies a higher model cost.
- Choose a Hybrid SLMs vs LLM system if:
- Your organisation has both simple and very complex use cases.
- You want to route easy queries to SLM and escalate only the toughest 10–20% to LLM.
- You want the best mix of speed, accuracy, cost and compliance.
In practice, most enterprises in 2025 discover that 70–80% of their use cases fit comfortably into the SLM or hybrid bucket not pure LLM‑only.
Final recommendation
If there is one key message from real‑world GenAI implementation, it is this:
The best AI model is not the biggest one. It is the one that solves your problem reliably, safely, and economically.
- For repetitive, domain‑specific, or rule‑based tasks → design around a Small Language Model with RAG and fine‑tuning.
- For deep reasoning, creativity, or long, complex text → bring in a Large Language Model where it truly adds value.
- For maximum value in 2025 → use a Hybrid SLM + LLM architecture that lets you scale cheaply on SLMs while reserving LLM power for the hardest problems.
FAQs
Q1: What is the main difference between SLMs vs LLMs, Small Language Models (SLMs) and Large Language Models (LLMs)?
SLMs are smaller, faster, and domain-specialized models that work well on repetitive, predictable tasks. LLMs are larger, more generalist models designed for complex reasoning and open-ended generation.
Q2: Why should my enterprise consider using an SLM instead of an LLM?
SLMs often offer much lower cost, faster responses, and stronger data privacy since they can be deployed on-premises. They excel in domain-specific tasks after fine-tuning on your data.
Q3: When do LLMs perform better than SLMs in enterprise AI?
LLMs are superior for tasks requiring deep multi-step reasoning, long document generation, creativity, and handling ambiguous or novel problems.
Q4: What is a hybrid SLMs vs LLMs system, and why is it recommended?
A hybrid system uses an SLM for simple, high-volume queries and defers complex tasks to an LLM, balancing cost, speed, and accuracy across workloads.
Q5: How do SLMs help with compliance and data privacy issues?
SLMs can run entirely on your internal infrastructure, eliminating the need to send sensitive data to external cloud APIs, making it easier to comply with regulations like GDPR, HIPAA, or RBI.
Q6: How quickly can enterprises deploy SLMs vs LLMs?
SLMs often deploy in days due to simpler integrations and local hosting, while LLM deployments usually take weeks because of vendor onboarding, security reviews, and cloud setup.
Q7: Can developers fine-tune SLMs easily?
Yes. With techniques like LoRA and QLoRA, developers can fine-tune SLMs quickly and cost-effectively, enabling rapid iteration on enterprise-specific data.
Q8: Are SLMs suitable for all AI use cases in an enterprise?
No. SLMs work best for narrow, well-defined domains. For complex, open-ended, or creative tasks, LLMs remain essential.
Disclaimer: The views expressed are solely those of the author. Content is for informational purposes only.